
High volume and scalable F&O data import from an Azure DB
Let’s say you need to import 100k journal entries into D365 F&O every two hours, 24 hours a day and fully automated. You might have stable legacy system for Point of Sale or Production, but the transactions need to end up in F&O.
MS has built import and export capabilities into F&O. To integrate the transfer of these 100k entries you use SQL Server Integration Services to copy the legacy data to CSV files. Then, you use the Recurring Integration Scheduler (RIS) to import them into F&O.
Soon you discover that although it is a robust system, your first run doesn’t cope with the volume within the time limits. F&O application layer can handle thousands of concurrent users, but F&O data management by default sequentially works through the data on a single thread. Your first attempt of importing the 100k transactions takes over 4 hours, and that’s just to create the journals, not post them.

It is possible to configure multithreading. To do that you go to Workspaces > Data Management > Click the Framework Parameters tile > Entity Settings tab > Click Configure Entity Execution Parameters.
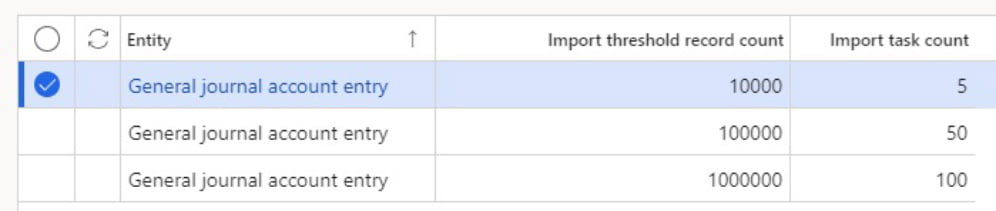
For importing journal entries, you configure 50 threads if the number of records is between 100k and one million (see image above). This works, but it’s not very flexible. If the data being imported varies in volume, you need to fine tune the configuration for best performance. This may take some tuning.
Out of the box F&O data import is limited to files like CSV, Excel or XLM documents. This is a bit limiting. Especially for high volume dataset it is better to read the data directly from the Azure database without having to move it into files first.
The above scenario highlights two of the reasons why the Axtend Data Management System (ADM) was created.
- Without ADM, optimizing import for multi-threaded performance takes manual tuning of the Entity Execution Parameters. ADM improves this by dynamically scaling to a multi-threaded import.
- Importing directly from an Azure database is not an option with the standard tools. Reading data from a database is more efficient and easier to work with, especially in error handling and validation. This is implemented with ADM.
Let’s walk through the same scenario as above but now with ADM.
The first difference is not having to bring the data into CSV files. ADM simply reads the data directly from Azure tables or views.
With the 100k journal entries you notice that there are on average 100 transactions per voucher. With ADM you can split the data into groups by a given field, and using the voucher seems to be a good fit. There are on average 100 transactions per voucher, so the result is 1,000 subsets. This will dynamically adapt to the data volume and thus decide how many threads are used. No need to configure import threshold settings for all possible cases of data volume like on the image above.
In addition, ADM can perform seamless pre- and post-process steps on a set of import actions. This enables you to post the ledger journals if they have successfully been imported. ADM also keeps tracks of any rows that have issues, so that you can follow up with those later and post them without re-posting those that went through the first time.
The bottom-line result is that in less than 30min, all 100k records have been migrated and posted to F&O. Using ADM for the process also took less time for you to configure and has fewer steps (no CSV files).





